The Blue Screen Strikes Back: CrowdStrike’s Update Glitch and Lessons for the AI-Native Age
Jaspreet Bindra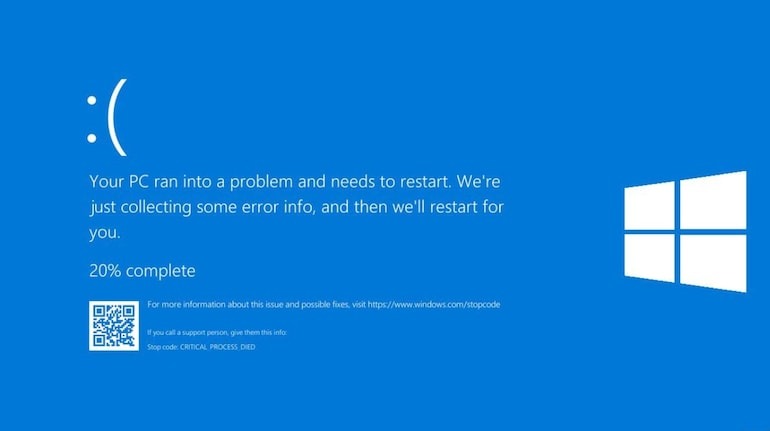
An Atlantic article (https://bit.ly/3YcLNV7 ) by Samuel Arbesman reminded me of a joke he has
there, beloved of software and cybersecurity engineers: “A software engineer walks into a bar. He
orders a beer. Orders zero beers. Orders 99,999,999,999 beers. Orders a lizard. Orders -1 beers.
Orders a ueicbksjdhd. The bar is still standing. A real customer walks in and asks where the
bathroom is. The bar bursts into flames.”
For us non-software types, it basically means that for every piece of software, you need to stress-
test it by flinging a variety of inputs ot it and induce errors from the system. However, many times, it
is what they did not anticipate or think about causes the system to crash. So, the best way to make a
system break-proof, is to try and break it through any means possible. Netflix made this approach
popular, with Chaos Monkey, an internal software that would randomly start attacking systems and
subsystems, to check how Netflix’s entire infrastructure would behave. Chaos Monkey helped Netflix
engineer a robust system to serve us movies on demand.
Global cybersecurity major Crowdstrike seems not have learnt from this well enough. On July 19th, a
blast from the past, the dreaded Blue Screen of Death (BSOD), suddenly reappeared across
computer screens everywhere – disrupting airports, hospitals, and businesses worldwide. The
culprit? A faulty patch from CrowdStrike of their Falcon software update that contained a glitch that
crashed Windows systems globally, exposing the fragility of our interconnected digital world.
So, what went wrong? The root of the problem was this faulty update, which contained an error that
caused a major malfunction in the core of the Windows operating system (known as the “kernel”),
leading to system crashes and the infamous “Blue Screen of Death” error message. Normally, such
problems could be fixed by simply undoing the update but this time the problem was so widespread
that each affected computer had to be manually fixed, leading to significant delays and disruptions.
It was a kind of disruption anticipated in 2000 with the now-infamous Y2K, just that it happened 24
years later!
Crowdstrike scrambled to build patches, but it did take a while to fix and resulted in missed flights,
acrimony, and lawsuits. Even as businesses limped back slowly from what probably is the largest IT
outage ever, what can we learn from this? This is even more pertinent given that we are entering
the age of AI, with even more powerful Large Language Models, autonomous AI agents, and the
looming inevitability of super-intelligence. Here are our top three learnings:
Importance of Throttled Rollouts: A glaring oversight in this incident seems to be the lack of a
throttled rollout. In software deployment, especially for critical systems, updates are normally
released gradually to a small percentage of users first. This approach allows for the detection of
issues before they can impact a larger user base. For instance, when GPT-4o was rolled out, it was
done in a throttled manner. Initially, it was made available to a limited number of free and Plus
users, with higher message limits. This careful and incremental approach ensured that any potential
issues could be identified and resolved early, preventing widespread disruption.
Redundancy and Resilience: This incident has highlighted the fragility of our digital infrastructure.
Organizations must invest in redundancies and resilience which includes having backup systems, a
multi-layered cybersecurity approach (utilizing solutions from multiple reputable vendors), and
robust incident response plans. Relying heavily on a single vendor for cybersecurity, as seen with
CrowdStrike’s extensive use, can create a single point of failure.
Proactive Monitoring and Testing: Before rolling out major updates, conducting a “pre-mortem” can
be invaluable. This exercise involves gathering key stakeholders to brainstorm potential failure
points before they happen. This includes rigorous and frequent testing of updates in staging
environments that closely mirror production systems. Additionally, continuous real-time monitoring,
powered by advanced analytics and machine learning, can detect anomalies and potential threats
early on. Implementing automated rollback mechanisms can also act as a safety net, providing a
rapid solution when unexpected issues arise.
As said before, all of this is even more relevant in the AI era. The systems that run our world are not
built by a single entity, but a smorgasbord of interconnected computers, servers and data centres,
what we loosely call the cloud. This outage also made apparent the fact that the threat of the ‘end of
the world’ could be more because of a mundane IT failure than the much-ballyhooed arrival of an AI
super intelligence. As an article (https://bit.ly/3SbDXan ) in the New York Times quotes TS Eliot: “This
is the way the world ends/ Not with a bang but a whimper.”
(Additional inputs from this article from Anuj Magazine, co-founder AI&Beyond and a
cybersecurity expert)

